Как создать базу данных в среде SQL Server. Создание базы данных. Присоединение и отсоединение баз данных
Пример создания локальной базы данных Microsoft SQL Server в MS Visual Studio
В данной теме показано решение задачи создания базы данных типа SQL Server с помощью MS Visual Studio . Рассматриваются следующие вопросы:
- работа с окном Server Explorer в MS Visual Studio ;
- создание локальной базы данных типа SQL Server Database ;
- создание таблиц в базе данных;
- редактирование структур таблиц;
- связывание таблиц базы данных между собой;
- внесение данных в таблицы средствами MS Visual Studio .
Условие задачи
Используя средства MS Visual Studio создать базу данных типа MS SQL Server с именем Education. База данных содержит две таблицы Student и Session. Таблицы между собой связаны по некоторыму полю.
Структура первой таблицы «Student».
Структура второй таблицы “Session ”.

Выполнение
1. Загрузить MS Visual Studio .
2. Активировать окно Server Explorer .
Для работы с базами данных корпорация Microsoft предлагает облегченный сервер баз данных Microsoft SQL Server . Существуют разные версии Microsoft SQL Server , например: Microsoft SQL Server 2005 , Microsoft SQL Server 2008 , Microsoft SQL Server 2014 и прочие версии.
Загрузить эти версии можно с сайта Microsoft www.msdn.com .
Этот сервер отлично подходит для работы с базами данных. Он бесплатен и имеет графический интерфейс для создания и администрирования баз данных с помощью SQL Server Management Tool .
Прежде всего, перед созданием базы данных, нужно активировать утилиту Server Explorer . Для этого, в MS Visual Studio нужно вызвать (рис. 1)
View -> Server Explorer Рис. 1. Вызов Server Explorer
Рис. 1. Вызов Server Explorer
После вызова окно Server Explorer будет иметь приблизительный вид, как показано на рисунке 2.
 Рис. 2. Окно Server Explorer
Рис. 2. Окно Server Explorer
3. Создание базы данных “Education”.
Чтобы создать новую базу данных, базирующуюся на поставщике данных Microsoft SQL Server , нужно кликнуть на узле Data Connections, а потом выбрать “Create New SQL Server Database … ” (рис. 3).
 Рис. 3. Вызов команды создания базы данных SQL Server
Рис. 3. Вызов команды создания базы данных SQL Server
В результате откроется окно «Create New SQL Server Database » (рис. 4).
В окне (в поле «Server Name») указывается имя локального сервера, установленного на вашем компьютере. В нашем случае это имя “SQLEXPRESS ”.
В поле «New database name: » указывается имя создаваемой базы данных. В нашем случае это имя Education.
Опцию Use Windows Autentification нужно оставить без изменений и нажать кнопку OK .
 Рис. 4. Создание новой базы данных SQL Server 2008 Express
с помощью MS Visual Studio 2010
Рис. 4. Создание новой базы данных SQL Server 2008 Express
с помощью MS Visual Studio 2010
После выполненных действий, окно Server Explorer примет вид, как показано на рисунке 5. Как видно из рисунка 5, в список имеющихся баз данных добавлена база данных Education с именем
sasha-pc\sqlexpress.Education.dbo Рис. 5. Окно Server Explorer
после добавления базы данных Education
Рис. 5. Окно Server Explorer
после добавления базы данных Education
4. Объекты базы данных Education.
Если развернуть базу данных Education (знак «+ »), то можно увидеть список из следующих основных объектов:
- Database Diagrams – диаграммы базы данных. Диаграммы показывают связи между таблицами базы данных, отношения между полями разных таблиц и т.п.;
- Tables – таблицы, в которых помещаются данные базы данных;
- Views – представления. Отличие между представлениями и таблицами состоит в том, что таблицы баз данных содержат данные, а представления данных не содержат их, а содержимое выбирается из других таблиц или представлений;
- Stored procedures – хранимые процедуры. Они представляют собою группу связанных операторов на языке SQL, что обеспечивает дополнительную гибкость при работе с базой данных.
5. Создание таблицы Student.
На данный момент база данных Education абсолютно пустая и не содержит никаких объектов (таблиц, сохраненных процедур, представлений и т.д.).
Чтобы создать таблицу, нужно вызвать контекстное меню (клик правой кнопкой мышки) и выбрать команду “Add New Table ” (рисунок 6).
 Рис. 6. Команда добавления новой таблицы
Рис. 6. Команда добавления новой таблицы
Существует и другой вариант добавления таблицы базы данных с помощью команд меню Data:
Data -> Add New -> Table
Рис. 7. Альтернативный вариант добавления новой таблицы
В результате откроется окно добавления таблицы, которое содержит три столбца (рисунок 8). В первом столбце “Column Name” нужно ввести название соответствующего поля таблицы базы данных. Во втором столбце “Data Type” нужно ввести тип данных этого поля. В третьем столбце “ Allow Nulls ”указывается опция о возможности отсутствия данных в поле.
 Рис. 8. Окно создания новой таблицы
Рис. 8. Окно создания новой таблицы
С помощью редактора таблиц нужно сформировать таблицу Student как изображено на рисунке 9. Имя таблицы нужно задать при ее закрытии.
В редакторе таблиц можно задавать свойства полей в окне Column Properties. Для того, чтобы задать длину строки (nvchar) в символах, в окне Column Properties есть свойство Length. По умолчанию значения этого свойства равно 10.
 Рис. 9. Таблица Student
Рис. 9. Таблица Student
Следующим шагом нужно задать ключевое поле. Это осуществляется вызовом команды “Set Primary Key ” из контекстного меню поля Num_book. С помощью ключевого поля будут установлены связи между таблицами. В нашем случае ключевым полем есть номер зачетной книжки.
 Рис. 10. Задание ключевого поля
Рис. 10. Задание ключевого поля
После установки первичного ключа окно таблицы будет иметь вид как изображено на рисунке 11.
 Рис. 11. Таблица Student
после окончательного формирования
Рис. 11. Таблица Student
после окончательного формирования
Теперь можно закрыть таблицу. В окне сохранения таблицы нужно задать ее имя – Student (рис. 12).
 Рис. 12. Ввод имени таблицы Student
Рис. 12. Ввод имени таблицы Student
6. Создание таблицы Session.
По образцу создания таблицы Student создается таблица Session.
На рисунке 13 изображен вид таблицы Session после окончательного формирования. Первичный ключ (Primary Key ) устанавливается в поле Num_book. Имя таблицы задается Session.

Рис. 13. Таблица Session
После выполненных действий, в окне Server Explorer будут отображаться две таблицы Student и Session.
Таким образом, в базу данных можно добавлять любое количество таблиц.
7. Редактирование структуры таблиц.
Бывают случаи, когда нужно изменить структуру таблицы базы данных.
Для того, чтобы вносить изменения в таблицы базы данных в MS Visual Studio, сначала нужно снять опцию “Prevent Saving changes that require table re-creation ” как показано на рисунке 14. Иначе, MS Visual Studio будет блокировать внесения изменений в ранее созданную таблицу. Окно Options, показанное на рисунке 14 вызывается из меню Tools в такой последовательности:
Tools -> Options -> Database Tools -> Table and Database Designers Рис. 14. Опция “Prevent Saving changes that require table re-creation
”
Рис. 14. Опция “Prevent Saving changes that require table re-creation
”
После настройки можно изменять структуру таблицы. Для этого используется команда “Open Table Definition ” (рисунок 15) из контекстного меню, которая вызывается для выбранной таблицы (правый клик мышкой).
 Рис. 15. Вызов команды “Open Table Definition
”
Рис. 15. Вызов команды “Open Table Definition
”
Также эта команда размещается в меню Data:
Data -> Open Table DefinitionПредварительно таблицу нужно выделить.
8. Установление связей между таблицами.
В соответствии с условием задачи, таблицы связаны между собою по полю Num_book.
Чтобы создать связь между таблицами, сначала нужно (рисунок 16):
- выделить объект Database Diagram;
- выбрать команду Add New Diagram из контекстного меню (или из меню Data).

Рис. 16. Вызов команды добавления новой диаграммы
В результате откроется окно добавления новой диаграммы Add Table (рисунок 17). В этом окне нужно выбрать последовательно две таблицы Session и Student и нажать кнопку Add.
 Рис. 17. Окно добавления таблиц к диаграмме
Рис. 17. Окно добавления таблиц к диаграмме
 Рис. 18. Таблицы Student
и Session
после добавления их к диаграмме
Рис. 18. Таблицы Student
и Session
после добавления их к диаграмме
Чтобы начать устанавливать отношение между таблицами, надо сделать клик на поле Num_book таблицы Student, а потом (не отпуская кнопку мышки) перетянуть его на поле Num_book таблицы Session.
В результате последовательно откроются два окна: Tables and Columns (рис. 19) и Foreign Key Relationship (рис. 20), в которых нужно оставить все как есть и подтвердить свой выбор на OK.
В окне Tables and Columns задается название отношения (FK_Session_Student ) и названия родительской (Student) и дочерней таблиц.
 Рис. 19. Окно Tables
and Columns
Рис. 19. Окно Tables
and Columns
 Рис. 20. Окно настройки свойств отношения
Рис. 20. Окно настройки свойств отношения
После выполненных действий будет установлено отношение между таблицами (рисунок 21).
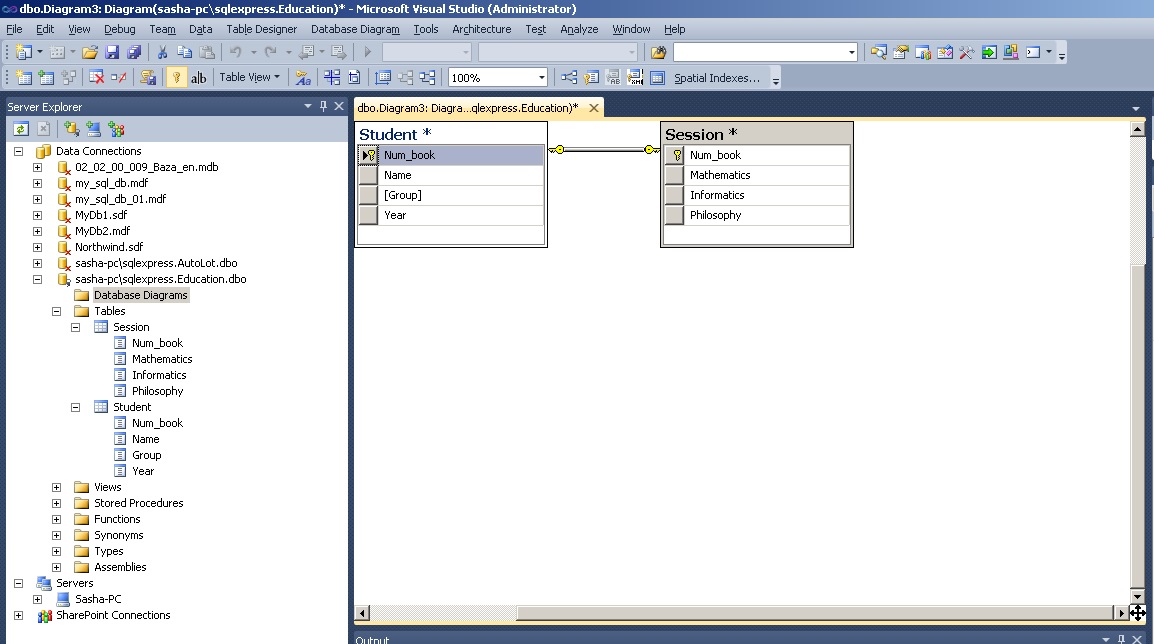 Рис. 21. Отношение между таблицами Student
и Session
Рис. 21. Отношение между таблицами Student
и Session
Сохранение диаграммы осуществляется точно также как и сохранение таблицы. Имя диаграммы нужно выбрать на свое усмотрение (например Diagram1).
После задания имени диаграммы откроется окно Save, в котором нужно подтвердить свой выбор (рисунок 22).
 Рис. 22. Подтверждение сохранения изменений в таблицах
Рис. 22. Подтверждение сохранения изменений в таблицах
9. Ввод данных в таблицы.
Система Microsoft Visual Studio разрешает непосредственно вносить данные в таблицы базы данных.
В нашем случае, при установлении связи (рис. 19) первичной (Primary Key Table ) избрана таблица Student. Поэтому, сначала нужно вносить данные в ячейки именно этой таблицы. Если попробовать сначала внести данные в таблицу Session, то система заблокирует такой ввод с выводом соответствующего сообщения.
Чтобы вызвать режим ввода данных в таблицу Student, нужно вызвать команду Show Table Data из контекстного меню (клик правой кнопкой мышки) или с меню Data (рис. 23).
 Рис. 23. Команда Show Table Data
Рис. 23. Команда Show Table Data
Откроется окно, в котором нужно ввести входные данные (рис. 24).
 Рис. 24. Ввод данных в таблице Student
Рис. 24. Ввод данных в таблице Student
После внесения данных в таблицу Student нужно внести данные в таблицу Session.
При внесении данных в поле Num_book таблицы Session нужно вводить точно такие же значения, которые введены в поле Num_book таблицы Student (поскольку эти поля связаны между собой).
Например, если в поле Num_book таблицы Student введены значения “101”, “102”, “103” (см. рис. 24), то следует вводить именно эти значения в поле Num_book таблицы Session. Если попробовать ввести другое значение, система выдаст приблизительно следующее окно (рис. 25).
 Рис. 25. Сообщение об ошибке ввода данных связанных таблиц Student
и Session
Рис. 25. Сообщение об ошибке ввода данных связанных таблиц Student
и Session
Таблица Session с введенными данными изображена на рисунке 26.
Microsoft SQL Server 005 - Пример создания «*.mdf» файла локальной базы данных Microsoft SQL Server в Microsoft Visual Studio
Введение
Эта статья открывает небольшой цикл, посвященный азам взаимодействия с базами данных (БД) в Java и введению в SQL . Многие программы заняты обработкой и модификацией информации, её поддержкой в актуальном состоянии. Поскольку данные - весьма важная часть логики программ, то под них зачастую выделяют отдельное хранилище. Информация в нём структурирована и подчинена специальным правилам, чтобы обеспечить правильность обработки и хранения. Доступ к данным и их изменение осуществляется с помощью специального языка запросов - SQL (Structured Query Language). Система управления базами данных - это ПО, которое обеспечивает взаимодействие разных внешних программ с данными и дополнительные службы (журналирование, восстановление, резервное копирование и тому подобное), в том числе посредством SQL. То есть программная прослойка между данными и внешними программами с ними работающими. В этой части ответим на вопросы что такое SQL, что такое SQL сервер и создадим первую программу для взаимодействия с СУБД.Виды СУБД
Существует несколько видов СУБД по способу организации хранения данных:- Иерархические. Данные организованы в виде древовидной структуры. Пример - файловая система, которая начинается с корня диска и далее прирастает ветвями файлов разных типов и папок разной степени вложенности.
- Сетевые. Видоизменение иерархической, у каждого узла может быть больше одного родителя.
- Объектно-ориентированные. Данные организованы в виде классов/объектов c их атрибутами и принципами взаимодействия согласно ООП.
- Реляционные. Данные этого вида СУБД организованы в таблицах. Таблицы могут быть связаны друг с другом, информация в них структурирована.
SQL
Внешние программы формируют запросы к СУБД на языке управления данными Structured Query Language. Что такое SQL и чем отличается от привычных языков программирования? Одна из особенностей SQL – декларативность. То есть, SQL - декларативный язык . Это значит, что, вбивая команды, то есть, создавая запросы к SQL-серверу, мы описываем, что именно хотим получить, а не каким способом. Посылая серверу запрос SELECT * FROM CUSTOMER (приблизительный перевод с SQL на русский: «сделать выборку из таблицы COSTUMER, выборка состоит из всех строк таблица» ), мы получим данные по всем пользователям. Совершенно неважно, как и откуда сервер загрузит и сформирует интересующие нас данные. Главное – правильно сформулировать запрос.- Что такое SQL-Сервер и как он работает? Взаимодействие с СУБД происходит по клиент-серверному принципу. Некая внешняя программа посылает запрос в виде операторов и команд на языке SQL, СУБД его обрабатывает и высылает ответ. Для упрощения примем, что SQL Сервер = СУБД.
- Data Definition Language (DDL ) – определения данных. Создание структуры БД и её объектов;
- Data Manipulation Language(DML ) – собственно взаимодействие с данными: вставка, удаление, изменение и чтение;
- Transaction Control Language (TCL ) – управление транзакциями;
- Data Control Language(DCL ) – управление правами доступа к данным и структурам БД.
JDBC
В 80-е годы прошлого века персональные компьютеры типа PC XT/AT завоевали рынок. Во многом это произошло благодаря модульности их конструкции. Это означает, что пользователь мог довольно просто менять ту или иную составную часть своего компьютера (процессор, видеокарту, диски и тому подобное). Это замечательное свойство сохранилось и поныне: мы меняем видеокарту и обновляем драйвер (иногда он и вовсе обновляется сам, в автоматическом режиме). Чаще всего при таких манипуляциях ничего плохого не происходит, и существующие программы продолжат работать с обновившейся системой без переустановки. Аналогично и для работы в Java с СУБД. Для стандартизации работы с SQL-серверами взаимодействие с ней можно выполнять через единую точку - JDBC (Java DataBase Connectivity). Она представляет собой реализацию пакета java.sql для работы с СУБД. Производители всех популярных SQL-серверов выпускают для них драйверы JDBC. Рассмотрим схему ниже. Приложение использует экземпляры классов из java.sql . Затем мы передаем необходимые команды для получения/модификации данных. Далее java.sql через jdbc-драйвер взаимодействует с СУБД и возвращает нам готовый результат. Для перехода на СУБД другого производителя часто достаточно сменить JDBC и выполнить базовые настройки. Остальные части программы при этом не меняются.Первая программа
Приступим к практической части. Создадим Java-проект с помощью IDE JetBrains IntelliJ IDEA . Заметим, что редакция Ultimate Edition содержит в своём составе замечательный инструмент для работы с SQL и БД - Data Grip . Однако она платная для большинства пользователей. Так что нам для учебных целей остается использовать общедоступную IntelliJ IDEA Community Edition . Итак: Теперь мы умеем подключаться к СУБД и отключаться от неё. Каждый шаг отражается в консоли. При первом подключении к СУБД создаётся файл базы данных stockExchange.mv.db .Разбор кода
Собственно код: package sql. demo; import java. sql. *; public class StockExchangeDB { // Блок объявления констант public static final String DB_URL = "jdbc:h2:/c:/JavaPrj/SQLDemo/db/stockExchange" ; public static final String DB_Driver = "org.h2.Driver" ; public static void main (String args) { try { Class. forName (DB_Driver) ; //Проверяем наличие JDBC драйвера для работы с БД Connection connection = DriverManager. getConnection (DB_URL) ; //соединениесБД System. out. println ("Соединение с СУБД выполнено." ) ; connection. close () ; // отключение от БД System. out. println ("Отключение от СУБД выполнено." ) ; } catch (ClassNotFoundException e) { e. printStackTrace () ; // обработка ошибки Class.forName System. out. println ("JDBC драйвер для СУБД не найден!" ) ; } catch (SQLException e) { e. printStackTrace () ; // обработка ошибок DriverManager.getConnection System. out. println ("Ошибка SQL !" ) ; } } }Блок констант:
- DB_Driver : Здесь мы определили имя драйвера, которое можно узнать, например, кликнув мышкой на подключенную библиотеку и развернув её структуру в директории lib текущего проекта.
- DB_URL : Адрес нашей базы данных. Состоит из данных, разделённых двоеточием:
- Протокол=jdbc
- Вендор (производитель/наименование) СУБД=h2
- Расположение СУБД, в нашем случае путь до файла (c:/JavaPrj/SQLDemo/db/stockExchange). Для сетевых СУБД тут дополнительно указываются имена или IP адреса удалённых серверов, TCP/UDP номера портов и так далее.
Обработка ошибок:
Вызов методов нашего кода может вернуть ошибки, на которые следует обратить внимание. На данном этапе мы просто информируем о них в консоли. Заметим, что ошибки при работе с СУБД - это чаще всего SQLException .Логика работы:
- Class.forName (DB_Driver) – убеждаемся в наличии соответствующего JDBC-драйвера (который мы ранее загрузили и установили).
- DriverManager.getConnection (DB_URL) – устанавливаем соединение СУБД. По переданному адресу, JDBC сама определит тип и местоположение нашей СУБД и вернёт Connection, который мы можем использовать для связи с БД.
- connection.close() – закрываем соединение с СУБД и завершаем работу с программой.
Разновидность языка, применяемая в конкретной СУБД, называется диалектом SQL . Например, диалект СУБДOracleназываетсяPL / SQL ; вMSSQLServerиDB2 применяется диалектTransact - SQL ; вInterbaseиFirebird–isql . Каждый диалектSQLсовместим до определенной степени со стандартомSQL, но может иметь отличия и специфические расширения языка, поэтому для выяснения синтаксиса того или иногоSQL-оператора следует в первую очередь смотретьHelp конкретной СУБД.
Для операций над базами данных и таблицами в стандарте sql предусмотрены операторы:
Ниже приводится синтаксис этих операторов по стандарту SQL92. Поскольку их синтаксис в СУБД может отличаться от стандарта, при выполнении лабораторной работы рекомендуется обращаться к справочной системе СУБД.
Имена объектов базы данных (таблиц, столбцов и др.) могут состоять из буквенно-цифровых символов и символа подчеркивания. Специальные символы (@$# и т.п.) обычно указывают на особый тип таблицы (системная, временная и др.). Не рекомендуется использовать в именах национальные (русские) символы, пробелы и зарезервированные слова, но если они всё же используются, то такие имена следует писать в кавычках ".." или в квадратных скобках [..].
Далее при описании конструкций операторов SQLбудут использоваться следующие обозначения: в квадратных скобках записываются необязательные части конструкции; альтернативные конструкции разделяются вертикальной чертой | ; фигурные скобки {} выделяют логические блоки конструкции; многоточие… указывает на то, что предшествующая часть конструкции может многократно повторяться. «Раскрываемые» конструкции записываются в угловых скобках < >.
Создание базы данных
CREATE DATABASE Имя_базы_данных
Удаление одной и более баз данных
DROP DATABASE Имя_базы_данных [,Имя_базы_данных …]
Объявление текущей базы данных
USE Имя_базы_данных –- в SQL Server и MySQL
SET DATABASE Имя _ базы _ данных – в Firebird
Создание таблицы
CREATE TABLE Имя_таблицы (
<описание_столбца> [, <описание_столбца> |
<ограничение_целостности_таблицы> …]
< описание_столбца >
Имя_столбца ТИП
{NO ACTION|CASCADE|SET DEFAULT|SET NULL}]
ТИП столбца может быть либо стандартным типом данных (см. таблицу 1), либо именем домена (см. п.6.2).
Некоторые СУБД позволяют создавать вычислимые столбцы (computed columns ). Это виртуальные столбцы, значение которых не хранится в физической памяти, а вычисляется сервером СУБД при всяком обращении к этому столбцу по формуле, заданной при объявлении этого столбца. В формулу могут входить значения других столбцов этой строки, константы, встроенные функции и глобальные переменные.
Описание вычислимого столбца в SQL Server имеет вид:
<описание_столбца> Имя_столбца AS выражение
Описание вычислимого столбца в Firebird имеет вид:
<описание_столбца> Имя_столбца COMPUTED BY <выражение>
СУБД MySQL 3.23 вычислимые столбцы не поддерживает.
< >
CONSTRAINT Имя_ограничения_целостности
{UNIQUE|PRIMARY KEY}(список_столбцов_образующих_ключ )
|FOREIGN KEY (список _ столбцов _FK )
REFERENCES Имя_таблицы (список_столбцов_ PK )
{NO ACTION|CASCADE|SET DEFAULT|SET NULL}]
{NO ACTION|CASCADE|SET DEFAULT|SET NULL}]
|CHECK (условие_проверки )
Некоторые СУБД допускают объявление врéменных таблиц (существующих только во время сеанса). В SQL Server имена временных таблиц должны начинаться с символа # (локальные временные таблицы, видимые только создавшему их пользователю) или ## (глобальные таблицы, видимые всем пользователям); в MySQL для создания временных таблиц используется ключевое слово TEMPORARY, например:
CREATE TEMPORARY TABLE … (далее синтаксис см. CREATE TABLE).
Изменение структуры таблицы
Используется для изменения типа столбцов существующих таблиц, добавления и удаления столбцов и ограничений целостности.
ALTER TABLE Имя_таблицы
Изменение типа столбца (в SQLServerиFirebird)
ALTER COLUMN Имя_столбца новый_ТИП
Изменение типа, имени и ограничений столбца (в MySQL)
CHANGE COLUMN Имя_столбца <описание_столбца>
Добавление обычного или вычислимого столбца
|ADD <описание_столбца >
Добавление ограничения целостности
| ADD
<ограничение_целостности_таблицы >
Удаление столбца
|DROP COLUMN Имя_столбца
Удаление ограничения целостности
|DROP CONSTRAINT Имя_ограничения_целостности
Включение или отключение проверки ограничений целостности
ВMSSQLServer
|{CHECK|NO CHECK} CONSTRAINT
{Список_имен_ограничений_целостности |ALL}
Удаление таблицы
DROP TABLE Имя_таблицы
Далее рассмотрим, как при создании новых таблиц командой CREATETABLEили изменении структуры существующих таблиц командойALTERTABLEобъявить декларативные ограничения целостности (подробнее они описаны в п.4.2) .
1. Обязательное наличие данных (NULL–значения)
Объявляется словом NULL(столбец может иметь пустые ячейки) илиNOT NULL(столбец обязательный). По умолчанию принимаетсяNULL.
Пример создания таблицы 7:
CREATE TABLE Clients(
ClientName NVARCHAR (60) NOT NULL ,
DateOfBirth DATE NULL ,
Phone CHAR (12)); -- по умолчанию тоже NULL
2. Значение по умолчанию (DEFAULT)
Значение по умолчанию можно задать для каждого столбца таблицы. Если при модификации ячейки ее новое значение не указано, сервер вставляет значение по умолчанию. Значение по умолчанию может быть NULL, константой, вычислимым выражением или системной функцией.
Рассмотрим пример создания таблицы Orders (Заказы). Столбец OrderDate принимает по умолчанию значение текущей даты, а столбец Quantity (количество) по умолчанию равен 0.
CREATE TABLE Orders(
OrderNum INT NOT NULL , -- номер заказа
OrderDate DATETIME NOT NULL -- дата заказа
DEFAULT GetDate(),
Функция GetDate() возвращает текущую дату 8
Quantity SMALLINT NOT NULL -- кол-во товара, DEFAULT 0);
3. Объявление первичных ключей (PRIMARYKEY)
Простой первичный ключ объявляется словами PRIMARYKEYпри создании таблицы. Например,
CREATE TABLE Staff(-- таблица "Работники"
TabNum INT PRIMARY KEY , -- первичный ключ
WName NVARCHAR (40) NOT NULL , -- ФИО
... -- описание прочих столбцов );
Составной первичный ключ объявляется иначе:
-- способ 1 (объявление PK при создании таблицы)
CREATE TABLE Clients(
PasSeria NUMERIC (4,0)NOT NULL ,-- серия паспорта
PasNumber NUMERIC (6,0)NOT NULL ,-- номер паспорта
Name NVARCHAR (40)NOT NULL ,
Phone CHAR (12),
-- объявление составного первичного ключа
CONSTRAINT Clients_PK
PRIMARY KEY (PasSeria,PasNumber));
-- способ 2(PK объявляется после создания таблицы)
-- сначала создаем таблицу без PK
CREATE TABLE Clients(
PasSeria NUMERIC (4,0)NOT NULL ,--серия паспорта
PasNumber NUMERIC (6,0)NOT NULL ,--номер паспорта
ClientName NVARCHAR (40)NOT NULL ,
Phone CHAR (12));
-- модификация таблицы – добавляем РК
ALTER TABLE Clients
ADD CONSTRAINT Clients_PK
PRIMARY KEY (PasSeria,PasNumber);
4. Уникальность столбцов (UNIQUE)
Подобно Primary Key указывает, что столбец или группа столбцов не могут содержать повторяющихся значений, но не являютсяPK . Все столбцы, объявленныеUNIQUE, должны бытьNOTNULL. Пример объявления простого уникального столбца:
CREATE TABLE Students(
SCode INT PRIMARY KEY , -- суррогатный РК
FIO NVARCHAR (40) NOT NULL , -- ФИО
RecordBook CHAR (6) NOT NULL UNIQUE ); -- № зачетки
Пример объявления составного уникального поля:
CREATE TABLE Staff(-- таблица " Работники "
TabNum INT PRIMARY KEY , -- табельный номер
WName NVARCHAR (40) NOT NULL , -- ФИО
PasSeria NUMERIC (4,0) NOT NULL , -- серия паспорта
PasNumber NUMERIC (6,0) NOT NULL , -- номер паспорта
-- объявление составного уникального поля
CONSTRAINT Staff_UNQ UNIQUE (PasSeria,PasNumber));
5. Ограничения на значения столбца (CHECK)
Это ограничение позволяет указать диапазон, список или «маску» логически допустимых значений столбца.
Пример создания таблицы Workers (Работники) :
CREATE TABLE Workers(
-- табельные номера 4-значные
TabNum INT PRIMARY KEY
CHECK (TabNum BETWEEN 1000 AND 9999),
Name VARCHAR (60) NOT NULL , -- ФИО сотрудника
-- пол – буква " м " или " ж "
Gentry CHAR (1) NOT NULL
CHECK (Gentry IN ("м","ж")),
Возраст не менее 14 лет
Age SMALLINT NOT NULL CHECK (Age>=14),
--№ свидет-ва пенсионного страхования (по маске)
PensionCert CHAR (14)
CHECK (PensionSert LIKE ""));
В этом примере показаны разные типы проверок. Диапазон допустимых значений указывается конструкцией BETWEEN…AND; обычные условия (как для столбцаAge ) используют знаки сравнений =, <>, >, >=, <, <=, связанные при необходимости логическими операциямиAND,OR,NOT(например,Age >=14ANDAge <=70); для указания списка допустимых значений используется предикатINи его отрицаниеNOTIN; конструкция
LIKEмаска_допустимых_значений EXCEPTсписок_исключений
используется для задания маски допустимых значений строковых столбцов. В маске применяются два спецсимвола: «%» – произвольная подстрока, и «_» – любой единичный символ. Конструкция EXCEPTявляется необязательной.
В условии отбора CHECKмогут сравниваться значения двух столбцов одной таблицы и столбцы разных таблиц.
Каждый из нас регулярно сталкивается и пользуется различными базами данных. Когда мы выбираем адрес электронной почты, мы работаем с базой данных. Базы данных используют поисковые сервисы, банки для хранения данных о клиентах и т.д.
Но, несмотря на постоянное использование баз данных, даже для многих разработчиков программных систем остается много «белых пятен» из-за разного толкования одних и тех же терминов. Мы дадим краткое определение основных терминов баз данных перед рассмотрением языка SQL. Итак.
База данных - файл или набор файлов для хранения упорядоченных структур данных и их взаимосвязей. Очень часто базой данных называют систему управления - это только хранилище информации в определенном формате и может работать с различными СУБД.
Таблица - представим себе папку, в которой хранятся документы, сгруппированные по определенному признаку, например список заказов за последний месяц. Это и есть таблица в компьютерной Отдельная таблица имеет свое уникальное имя.
Тип данных - вид информации, разрешенной для хранения в отдельном столбце или строке. Это могут быть числа или текст определенного формата.
Столбец и строка - все мы работали с электронными таблицами, в которых также присутствуют строки и столбцы. Любая реляционная база данных работает с таблицами аналогичным образом. Строки иногда называют записями.
Первичный ключ - каждая строка таблицы может иметь один или несколько столбцов для ее уникальной идентификации. Без первичного ключа очень трудно производить обновление, изменение и удаление нужных строк.
Что такое SQL?
SQL (англ. - язык структурированных запросов) был разработан только для работы с базами данных и в настоящий момент является стандартом для всех популярных СУБД. Синтаксис языка состоит из небольшого количества операторов и прост в изучении. Но, несмотря на внешнюю простоту, он позволяет создание sql запросов для сложных операций с БД любого размера.
С 1992 г. существует общепринятый стандарт, называемый ANSI SQL. Он определяет базовый синтаксис и функции операторов и поддерживается всеми лидерами рынка СУБД, такими как ORACLE Рассмотреть все возможности языка в одной небольшой статье невозможно, поэтому мы кратко рассмотрим только основные SQL запросы. Примеры наглядно показывают простоту и возможности языка:
- создание баз и таблиц;
- выборка данных;
- добавление записей;
- модификация и удаление информации.
Типы данных SQL
Все столбцы в таблице базы данных хранят один тип данных. Типы данных в SQL такие же, как и в других языках программирования.
Создаем таблицы и базы данных

Создавать новые базы, таблицы и другие запросы в SQL можно двумя способами:
- Операторами SQL через консоль СУБД
- Используя интерактивные средства администрирования, входящие в состав сервера баз данных.
Создается новая база данных оператором CREATE DATABASE <наименование базы данных>; . Как видим, синтаксис прост и лаконичен.
Таблицы внутри базы данных создаем оператором CREATE TABLE со следующими параметрами:
- наименование таблицы
- имена и типы данных столбцов
В качестве примера создадим таблицу Commodity со следующими столбцами:
Создаем таблицу:
CREATE TABLE Commodity
(commodity_id CHAR(15) NOT NULL,
vendor_id CHAR(15) NOT NULL,
commodity_name CHAR(254) NULL,
commodity_price DECIMAL(8,2) NULL,
commodity_desc VARCHAR(1000) NULL);
Таблица состоит из пяти столбцов. После наименования идет тип данных, столбцы разделяются запятыми. Значение столбца может принимать пустые значения (NULL) или должно быть обязательно заполнено (NOT NULL), и это определяется при создании таблицы.
Выборка данных из таблицы

Оператор выборки данных - самые часто используемые SQL запросы. Для получения информации необходимо указать, что мы хотим выбрать из такой таблицы. Вначале простой пример:
SELECT commodity_name FROM Commodity
После оператора SELECT указываем имя столбца для получения информации, а FROM определяет таблицу.
Результатом выполнения запроса будут все строки таблицы со значениями Commodity_name в том порядке, в котором они были внесены в базу данных т.е. без всякой сортировки. Для упорядочивания результата используется дополнительный оператор ORDER BY.
Для запроса по нескольким полям перечисляем их через запятую, как в следующем примере:
SELECT commodity_id, commodity_name, commodity_price FROM Commodity
Есть возможность получить как результат запроса значение всех столбцов строки. Для этого используется знак «*»:
SELECT * FROM Commodity
- Дополнительно SELECT поддерживает:
- Сортировку данных (оператор ORDER BY)
- Выбор согласно условиям (WHERE)
- Группировку срок (GROUP BY)
Добавляем строку

Для добавления строки в таблицу используются SQL запросы с оператором INSERT. Добавление может производиться тремя способами:
- добавляем новую целую строку;
- часть строки;
- результаты запроса.
Для добавления полной строки необходимо указать имя таблицы и значения столбцов (полей) новой строки. Приведем пример:
INSERT INTO Commodity VALUES("106 ", "50", "Coca-Cola", "1.68", "No Alcogol ,)
Пример добавляет в таблицу новый товар. Значения указываются после VALUES для каждого столбца. Если нет соответствующего значения для столбца, то необходимо указывать NULL. Столбцы заполняются значениями в порядке, указанном при создании таблицы.
В случае добавления только части строки необходимо явно указать наименования столбцов, как в примере:
INSERT INTO Commodity (commodity_id, vendor_id, commodity_name)
VALUES("106 ", ‘50", "Coca-Cola",)
Мы ввели только идентификаторы товара, поставщика и его наименование, а остальные поля отставили пустыми.
Добавление результатов запроса
В основном INSERT используется для добавления строк, но может использоваться и для добавления результатов оператора SELECT.
Изменение данных

Для изменения информации в полях таблицы базы данных необходимо использовать оператор UPDATE. Оператор может применяться двумя способами:
- Обновляются все строки в таблице.
- Только для определенной строки.
UPDATE состоит из трех основных элементов:
- таблица, в которой необходимо производить изменения;
- имена полей и их новые значения;
- условия выбора строк для изменения.
Рассмотрим пример. Допустим, у товара с ID=106 изменилась стоимость, поэтому эту строку необходимо обновить. Пишем следующий оператор:
UPDATE Commodity SET commodity_price = "3.2" WHERE commodity_id = "106"
Мы указали имя таблицы, в нашем случае Commodity, где будет производиться обновление, затем после SET - новое значение столбца и нашли нужную запись, указав в WHERE нужное значение ID.
Для изменения нескольких столбцов после оператора SET указываются несколько пар столбец-значение, разделенных запятыми. Смотрим пример, в котором обновляется наименование и цена товара:
UPDATE Commodity SET commodity_name=’Fanta’, commodity_price = "3.2" WHERE commodity_id = "106"
Для удаления информации в столбце можно присвоить ему значение NULL, если это позволяет структура таблицы. Необходимо помнить, что NULL - это именно «никакое» значение, а не нуль в виде текста или числа. Удалим описание товара:
UPDATE Commodity SET commodity_desc = NULL WHERE commodity_id = "106"
Удаление строк

SQL запросы на удаление строк в таблице выполняются оператором DELETE. Есть два варианта использования:
- в таблице удаляются определенные строки;
- удаляются все строки в таблице.
Пример удаления одной строки из таблицы:
DELETE FROM Commodity WHERE commodity_id = "106"
После DELETE FROM указываем имя таблицы, в которой будут удаляться строки. Оператор WHERE содержит условие, по которому будут выбираться строки для удаления. В примере мы удаляем строку товара с ID=106. Указывать WHERE очень важно т.к. пропуск этого оператора приведт к удалению всех строк в таблице. Это относится и к изменению значения полей.
В операторе DELETE не указываются наименования столбцов и метасимволы. Он полностью удаляет строки, а удалить отдельный столбец он не может.
Использование SQL в Microsoft Access

Обычно используется в интерактивном режиме для создания таблиц, баз данных, для управления, изменения, анализа данных в базе данных и с целью внедрить запросы SQL Access через удобный интерактивный конструктор запросов (Query Designer), используя который можно построить и немедленно выполнить операторов SQL любой сложности.
Также поддерживается режим доступа к серверу, при котором СУБД Access может использоваться как генератор SQL-запросов к любому ODBC источнику данных. Эта возможность позволяет приложениям Access взаимодействовать с любого формата.
Расширения SQL
Поскольку SQL запросы не имеют всех возможностей процедурных языков программирования, таких как циклы, ветвления и т.д., производители СУБД разрабатывают свой вариант SQL с расширенными возможностями. В первую очередь это поддержка хранимых процедур и стандартных операторов процедурных языков.
Наиболее распространенные диалекты языка:
- Oracle Database - PL/SQL
- Interbase, Firebird - PSQL
- Microsoft SQL Server - Transact-SQL
- PostgreSQL - PL/pgSQL.
SQL в Интернет
СУБД MySQL распространяется под свободной лицензией GNU General Public License. Имеется коммерческая лицензия с возможностью разработки заказных модулей. Как составная часть входит в наиболее популярные сборки Интернет-серверов, таких как XAMPP, WAMP и LAMP, и является самой популярной СУБД для разработки приложений в сети Интернет.
Была разработана компанией Sun Microsystems и в настоящий момент поддерживается корпорацией Oracle. Поддерживаются базы данных размером до 64 терабайт, стандарт синтаксиса SQL:2003, репликация баз данных и облачных сервисов.
Аннотация: Определяется процесс создания базы данных. Описываются операторы создания, изменения базы данных. Рассматривается возможность указания имени файла или нескольких файлов для хранения данных, размеров и местоположения файлов. Анализируются операторы создания, изменения, удаления пользовательских таблиц. Приводится описание параметров для объявления столбцов таблицы. Дается понятие и характеристика индексов. Рассматриваются операторы создания и изменения индексов. Определяется роль индексов в повышении эффективности выполнения операторов SQL.
База данных
Создание базы данных
В различных СУБД процедура создания баз данных обычно закрепляется только за администратором баз данных . В однопользовательских системах принимаемая по умолчанию база данных может быть сформирована непосредственно в процессе установки и настройки самой СУБД. Стандарт SQL не определяет, как должны создаваться базы данных , поэтому в каждом из диалектов языка SQL обычно используется свой подход. В соответствии со стандартом SQL, таблицы и другие объекты базы данных существуют в некоторой среде. Помимо всего прочего, каждая среда состоит из одного или более каталогов , а каждый каталог – из набора схем . Схема представляет собой поименованную коллекцию объектов базы данных , некоторым образом связанных друг с другом (все объекты в базе данных должны быть описаны в той или иной схеме ). Объектами схемы могут быть таблицы , представления, домены, утверждения, сопоставления, толкования и наборы символов. Все они имеют одного и того же владельца и множество общих значений, принимаемых по умолчанию.
Стандарт SQL оставляет за разработчиками СУБД право выбора конкретного механизма создания и уничтожения каталогов , однако механизм создания и удаления схем регламентируется посредством операторов CREATE SCHEMA и DROP SCHEMA . В стандарте также указано, что в рамках оператора создания схемы должна существовать возможность определения диапазона привилегий, доступных пользователям создаваемой схемы . Однако конкретные способы определения подобных привилегий в разных СУБД различаются.
В настоящее время операторы CREATE SCHEMA и DROP SCHEMA реализованы в очень немногих СУБД. В других реализациях, например, в СУБД MS SQL Server, используется оператор CREATE DATABASE .
Создание базы данных в среде MS SQL Server
Процесс создания базы данных в системе SQL-сервера состоит из двух этапов: сначала организуется сама база данных , а затем принадлежащий ей журнал транзакций . Информация размещается в соответствующих файлах, имеющих расширения *.mdf (для базы данных ) и *.ldf . (для журнала транзакций ). В файле базы данных записываются сведения об основных объектах (таблицах , индексах , представлениях и т.д.), а в файле журнала транзакций – о процессе работы с транзакциями (контроль целостности данных, состояния базы данных до и после выполнения транзакций).
Создание базы данных в системе SQL-сервер осуществляется командой CREATE DATABASE . Следует отметить, что процедура создания базы данных в SQL-сервере требует наличия прав администратора сервера.
<определение_базы_данных> ::= CREATE DATABASE имя_базы_данных [ <определение_файла> [,...n] ] [,<определение_группы> [,...n] ] ] [ LOG ON {<определение_файла>[,...n] } ] [ FOR LOAD | FOR ATTACH ]
Рассмотрим основные параметры представленного оператора.
При выборе имени базы данных следует руководствоваться общими правилами именования объектов. Если имя базы данных содержит пробелы или любые другие недопустимые символы, оно заключается в ограничители (двойные кавычки или квадратные скобки). Имя базы данных должно быть уникальным в пределах сервера и не может превышать 128 символов.
При создании и изменении базы данных можно указать имя файла, который будет для нее создан, изменить имя, путь и исходный размер этого файла. Если в процессе использования базы данных планируется ее размещение на нескольких дисках, то можно создать так называемые вторичные файлы базы данных с расширением *.ndf . В этом случае основная информация о базе данных располагается в первичном (PRIMARY ) файле, а при нехватке для него свободного места добавляемая информация будет размещаться во вторичном файле . Подход, используемый в SQL-сервере, позволяет распределять содержимое базы данных по нескольким дисковым томам.
Параметр ON определяет список файлов на диске для размещения информации, хранящейся в базе данных .
Параметр PRIMARY определяет первичный файл . Если он опущен, то первичным является первый файл в списке.
Параметр LOG ON определяет список файлов на диске для размещения журнала транзакций . Имя файла для журнала транзакций генерируется на основе имени базы данных , и в конце к нему добавляются символы _log .
При создании базы данных можно определить набор файлов, из которых она будет состоять. Файл определяется с помощью следующей конструкции:
<определение_файла>::= ([ NAME=логическое_имя_файла,] FILENAME="физическое_имя_файла" [,SIZE=размер_файла ] [,MAXSIZE={max_размер_файла |UNLIMITED } ] [, FILEGROWTH=величина_прироста ])[,...n]
Здесь логическое имя файла – это имя файла, под которым он будет опознаваться при выполнении различных SQL-команд.
Физическое имя файла предназначено для указания полного пути и названия соответствующего физического файла, который будет создан на жестком диске. Это имя останется за файлом на уровне операционной системы.
Параметр SIZE определяет первоначальный размер файла; минимальный размер параметра – 512 Кб, если он не указан, по умолчанию принимается 1 Мб.
Параметр MAXSIZE определяет максимальный размер файла базы данных . При значении параметра UNLIMITED максимальный размер базы данных ограничивается свободным местом на диске.
При создании базы данных можно разрешить или запретить автоматический рост ее размера (это определяется параметром FILEGROWTH ) и указать приращение с помощью абсолютной величины в Мб или процентным соотношением. Значение может быть указано в килобайтах, мегабайтах, гигабайтах, терабайтах или процентах (%). Если указано число без суффикса МБ, КБ или %, то по умолчанию используется значение MБ. Если размер шага роста указан в процентах (%), размер увеличивается на заданную часть в процентах от размера файла. Указанный размер округляется до ближайших 64 КБ.
Дополнительные файлы могут быть включены в группу:
<определение_группы>::=FILEGROUP имя_группы_файлов <определение_файла>[,...n]
Пример 3.1 . Создать базу данных , причем для данных определить три файла на диске C, для журнала транзакций – два файла на диске C.
CREATE DATABASE Archive ON PRIMARY (NAME=Arch1, FILENAME=’c:\user\data\archdat1.mdf’, SIZE=100MB, MAXSIZE=200, FILEGROWTH=20), (NAME=Arch2, FILENAME=’c:\user\data\archdat2.mdf’, SIZE=100MB, MAXSIZE=200, FILEGROWTH=20), (NAME=Arch3, FILENAME=’c:\user\data\archdat3.mdf’, SIZE=100MB, MAXSIZE=200, FILEGROWTH=20) LOG ON (NAME=Archlog1, FILENAME=’c:\user\data\archlog1.ldf’, SIZE=100MB, MAXSIZE=200, FILEGROWTH=20), (NAME=Archlog2, FILENAME=’c:\user\data\archlog2.ldf’, SIZE=100MB, MAXSIZE=200, FILEGROWTH=20) Пример 3.1. Создание базы данных.